
Laurel Haak, PhD, is the Executive Director of ORCID. Tracey DePellegrin of Science Editor had a chance to talk with Haak about ORCID’s most recent activities, and their one millionth identifier!
SE: I like ORCID’s grassroots feel, combined with technology that’s actually adding value to many different types in research and publishing. What was the inspiration behind the original idea?
LH: ORCID came out of a growing realization that the status quo for managing information tied to researcher names was just not working. Automated algorithms for clustering author names, expert review of clusters, locally curated expert finders— all were partial and siloed solutions to the name ambiguity problem. The need for an approach that not only spanned organizations, sectors, and countries but also brought researchers into the solution as an equal partner drove a collaboration among publishers, universities, funders, associations, research institutes, repositories, researchers, and third-party systems, which ultimately created ORCID.
SE: For this to work, it seems as if you need a critical mass of individuals with ORCID IDs. What are the challenges in getting researchers onboard?
LH: ORCID is a nonprofit researcherdriven initiative. Scholars and researchers need to register for their own ORCID identifier and use it when they submit a grant, paper, dataset, thesis, or patent, to name a few. For this to happen, three things are required: it must be really easy to register, identifier collection points must be inserted into workflows so that the identifier becomes embedded in documents as they are publicly shared, and the benefit to the researcher of engaging with ORCID must be clear.
SE: I like this principle, listed on the ORCID website: “ORCID will transcend discipline, geographic, national and institutional boundaries.” Resonating with researchers and other stakeholders across the world is a key part of your messaging. How do you connect with researchers faceto-face?
LH: ORCID reserves a seat on its Board for a researcher-member, to get input at the highest level on our plans and policies. We host twice-yearly Outreach meetings and an annual CodeFest (see orcid.org/about/events). These are free and open to the entire community, to meet ORCID Board and staff, and learn the ways ORCID identifiers are being adopted and integrated. We just released a call for papers (www.orcidcasrai-2015.org/) for our next Outreach meeting, which will be held 18–19 May in Barcelona. Join us!
We also organize smaller workshops for specific audiences. We strive to be geographically diverse so that we can learn from the community how we can best serve their needs; to this end, we offer the Registry in nine languages. We’re fortunate to have more than 80 committed ambassadors (orcid.org/content/orcid-ambassadors) who help us engage researchers through presentations, posters, and assistance with translations.
SE: ORCID seems to be at most meetings I attend, whether it’s you, one of your staff, or those ubiquitous green iD pins! How do you (all) manage to be in so many places at once?
LH: We travel a lot. It is important for us to be there in person to listen. In 2014, we traveled to 22 countries on 4 continents for more than 50 meetings. That said, there are only so many places the seven of us can be—and we need to make sure we keep progressing the technology behind ORCID (and answer your questions) so we can’t be on the road all the time. We rely on digital technology to engage with the community: forums, webinars, our iDeas Board, and one-on-one phone calls. Our board members (orcid.org/about/team) and ambassadors help us organize events, present at meetings, post flyers, explain ORCID to their colleagues, and help spread the word through social media (follow us at @ ORCID_Org).
Also, we rely on our members: research funders, publishers, universities and research organizations, professional associations, and third-party system vendors. As more organizations and platforms integrate identifiers into research workflows—there are well over 100 collection points now— ORCID is becoming more recognized. What we hear from researchers is, “I keep being asked to include my identifier when I submit a [paper, grant, dataset, membership, review, abstract….].”
SE: Tell me more about your larger integration projects. What’s a recent case?
LH: Through the Alfred P. Sloan Foundation-funded Adoption and Integration program (orcid.org/content/adoptionand-integration-program), ORCID awarded each of nine organizations a small grant to develop integration use cases and prototypes. The program was recently completed (see blog [orcid.org/blog/2015/02/11/jump-startingorcid-adoption-and-integration-universitycommunity] and a final report was released [figshare.com/articles/Final_Report_Sloan_ORCID_Adoption_and_Integration_Program_2013_2014/1290632]). Not only did this lead to 13 new integrations in the university and association community, we also saw the first instance of an ORCID requirement for graduate students submitting theses, active integrations of ORCID iDs in VIVO and DSpace and plugins for Hydra (github.com/projecthydra-labs/orcid), library guides from Texas A&M (guides.library.tamu.edu/content.php?pid=553864&sid=4564756), videos from the University of Missouri (www.youtube.com/watch?v=213eh-QVpkI), and international conference presentations (or2014.helsinki.fi/?page_id=985). It was splendid! The program was at the heart of a huge increase in university implementations in 2014. It also provided a blueprint for others to emulate, one of them being the recent Jisc/ARMA ORCID pilot project (orcidpilot.jiscinvolve.org/wp/2015/02/03/next-steps-for-orcid-adoption-orcidconsortium-membership-for-the-uk/) for university implementation of ORCID in the UK.
SE: I like the one-size-does-not-fit-all approach. Even though you’re working to implement standards (in the end), the vibe is that of custom work and partnership. All this can seem complicated to those becoming familiar with ORCID. What clarifications are important to understanding ORCID?
LH: One of the most common misperceptions is that ORCID is a profile system. We are not. Rather, ORCID is a component of the plumbing that enables research communications. ORCID works to ensure that person names are machine readable, essentially distinguishing one researcher from another in cyberspace. All research information systems include database fields to store person names; ORCID works to ensure that these fields are augmented by two more: {person identifier source} and {person identifier}.
ORCID provides two core functions: a registry for researchers to obtain a unique identifier and manage linkages with activities and affiliations and application program interfaces (APIs) for organizations to support system-to-system communication and authentication. We make our code available under an open-source license (orcid.org/blog/2013/02/21/orcid-open-source), and annual public data files (orcid.org/content/orcid-public-data-file-use-policy) are posted under a Creative Commons CC0 waiver for free download.
SE: How can universities or research institutes (and the researchers) benefit from integrating ORCID with their workflows?
LH: Research organizations that integrate person identifier fields into their processes and systems benefit from a reduction in duplicate person records and increased interoperability. This supports more accurate and complete data for evaluation purposes, and means less time pestering researchers for information on their most recent contributions.
From the researcher’s perspective, there is no reason that updating a CV for an annual review should take three days!
Information on publications, funding, and other research activities should be readily available through machine-to-machine links (APIs). Researchers shouldn’t have to spend time to manually enter these data.
Without that data-entry burden, researchers have more time to focus on narrative, more time to do research. Having my person identifier embedded in documents such as grants, datasets, and papers, for example, means that search engines work better, people can find all of my contributions with minimal fuss, and I can easily repurpose information for researcher profiles, repositories, CVs, grant applications, websites, and more.
SE: I read that last year, ORCID issued its one millionth identifier! Did that person get a special pin or one of your hoodies?
LH: We provided an ORCID Store (www.cafepress.com/orcid) gift card to the 10 people registering around the one millionth issued identifier. We also held a contest for best tweet, awarded to David Isaak for his entry, “Your name is not unique, but your research activity is. Distinguish it with ORCID.” We sent him a customized mug with his ORCID iD and the 1M logo emblazoned on the sides.
SE: You’re familiar with the Council of Science Editors. Our community, like yours, is diverse and spans many types of organizations. Some publishers have already integrated ORCID IDs into their manuscript submission systems and published articles. Can you describe a few of the most important benefits to our authors, editors, and reviewers?
LH: Publishers play an important role in encouraging researchers to register and use their ORCID. Publishers deal with complex authorship issues, made even more complicated by siloed databases for authors and reviewers. Association publishers have the added complexity of databases for members and meetings. There are name ambiguity issues in each silo, and connecting names across the silos has proven to be very difficult.
Both publishers and authors will benefit from solving the name ambiguity problem. Integrating ORCID identifiers helps publishers better manage their author databases, identify reviewers, and deliver content. Authors can benefit from automatic updates of their ORCID record when new works are published. As ORCID is adopted, authors will be able to auto-populate forms with data from their ORCID record. They can connect contributions across authorship, reviewing, membership, and meeting activities. Distinguishing names with a persistent identifier that is embedded in works means it becomes easier to find a researcher’s works, which supports a whole host of use cases: improving the accuracy of name-based Internet searches, tracking an author’s subsequent publications, linking publications and datasets, and gathering usage statistics.
SE: Your new system for gathering feedback is great! Almost all companies say they want user feedback, but then the comments seem to go into a black hole. Not with ORCID’s Ideas Forum. People throw the word innovative around, but this Forum exemplifies innovation! Is the system catching on? What’s the verdict?
LH: As a community-driven organization, we are committed to having effective channels to listen. I am thrilled to hear so many positive comments about our accessibility and responsiveness. We launched the iDeas Forum (support.orcid.org/forums/175591-general) with the Registry in 2012. In 2014, we received 158 new ideas, so it is still going strong. We do pay attention to community requests and consider them when developing our annual development roadmaps. Last year, we logged 186 responses to open iDeas and addressed 43 items, several in a single release of a new Registry user interface (orcid.org/blog/2014/12/11/newfeature-friday-new-orcid-record-interface). We have a support desk (support.orcid.org/) that monitors user and member questions, answering about 600 tickets a month and an API users listserv where our members often answer each other’s questions. Our support team schedules a technical onboarding call with each new member, and we listen to the community at meetings, through email, and by watching Twitter. We continue to build out our Knowledge Base (support.orcid.org/knowledgebase) to enable easy search for answers and we recently launched a new Member Support Center (orcid.org/blog/2015/02/19/orcidmember-support-improving-on-excellence) that provides specific guidance for implementing ORCID, by community sector.
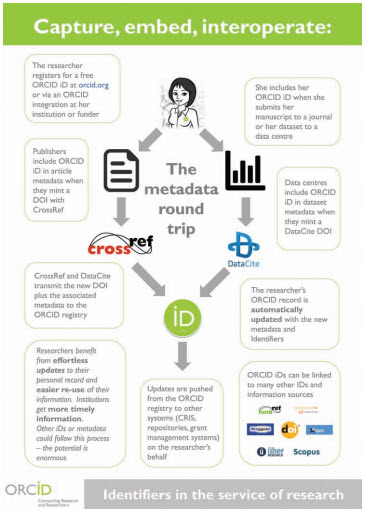
SE: OK, the inevitable last question: w hat’s next for ORCID?
LH: Top on the list this year are updates to our API to make it even more useful. But that’s largely behind the scenes. Up front and visible is our work with publishers and CrossRef to launch the first phase of ORCID record updates (orcid.org/blog/2015/01/13/new-webinar-metadataround-trip). These record updates provide the ability to push data on published articles to an ORCID record, for those authors who included their iD during manuscript submission. This will demonstrate clearly the benefit of plumbing with ORCID and opens the door to similar “round-trip” pathways (see Fig. 1) for dataset and grant information. Stay tuned!