SPEAKERS:
Tony Alves
Senior Vice President of Product Management
HighWire Press
Hopedale, Massachusetts
Allison Leung
Manager, Product Development
American Chemical Society
Washington, DC
Sven Molter
Senior Product Manager
Public Library of Science
Charlottesville, Virginia
REPORTER:
Natalie Ngo
Managing Editor, CJASN
American Society of Nephrology
Washington, DC
https://orcid.org/0000-0003-3908-7353
The world of preprints and preprint servers is continuously evolving to meet the needs of researchers, offering new services and pathways tied to traditional journal publishing. Some preprint servers are now utilizing artificial intelligence tools that provide language editing, image manipulation checks, and reference formatting for added quality assurance. With these integrations and the ease of online discovery, preprints are a viable source of new scholarship. Many journals have adopted formalized pathways for authors to transfer their work from a preprint server to a journal submission site. However, it is becoming increasingly common for journals to allow authors to transfer their submitted manuscripts to a preprint server. In this session, three industry professionals discuss models and workflows for preprint transfers.
Tony Alves, Senior Vice President of Product Management at HighWire Press, began by providing an overview of the Manuscript Exchange Common Approach (MECA)1 and its role in facilitating transfers. MECA, a National Information Standards Organization (NISO)-recommended practice, is a documented methodology describing how a software system should structure, assemble, and transmit files in a package “for transferring research articles from one system to another, so that the different systems don’t have to develop multiple pairwise solutions each and every time a system needs to talk to another system.”
According to Alves, who serves as co-chair of the NISO Standing Committee for MECA, the “primary objective was to alleviate author frustration [as] authors are often frustrated by redundancy of effort” (Figure 1). With that in mind, the NISO MECA Working Group designed a protocol that would transfer the files and minimal data needed to start a submission record, as well as transfer the reviews, which would help to alleviate reviewers’ frustrations over time wasted. The MECA team defined what files and data could be transferred but left it to the journals and authors to determine what was transferred.

MECA currently facilitates transfers between journals, between preprint servers and journals, and between journals and third-party production vendors, repositories, and other author-centered services. Still, in recognition of changing demands and technologies, the Standing Committee continues to augment its initiatives and investigations into application programming interface (API) solutions for transfer and peer review data communication protocols.
Allison Leung, Manager of Product Development at the American Chemical Society, next discussed transfers from ChemRxiv, a preprint server that is co-owned and co-managed by five different chemical societies from around the world. Launched in 2017, ChemRxiv has received over 12,000 preprints, which have been viewed or downloaded over 25 million times.2 Each preprint that is submitted to ChemRxiv is assigned a digital object identifier (DOI) and initially screened by a curator to ensure that it is chemistry related and scholarly in nature.
The direct journal transfer process from ChemRxiv launched in 2018 and has seen exponential growth in use. Leung shared several author benefits of the transfer process, including saving time and simplifying the journal selection process, as well as important journal benefits such as improved author experience and increased exposure. There are currently 150+ journals to which authors can transfer their ChemRxiv preprint, and the list is expanding. To transfer a preprint to a journal, authors simply select their preferred journal, confirm their selection, and then complete the submission upon receipt of an email from the receiving journal. If authors try to transfer their preprint to multiple journals simultaneously, they receive a pop-up warning message. Once the authors have confirmed their journal selection, the files are exported from ChemRxiv and uploaded as a package to the journal’s FTP site, which is then ingested by the receiving journal (Figure 2). The package includes the basic metadata, the manuscript PDF, and the supplemental information, which can be in any format.
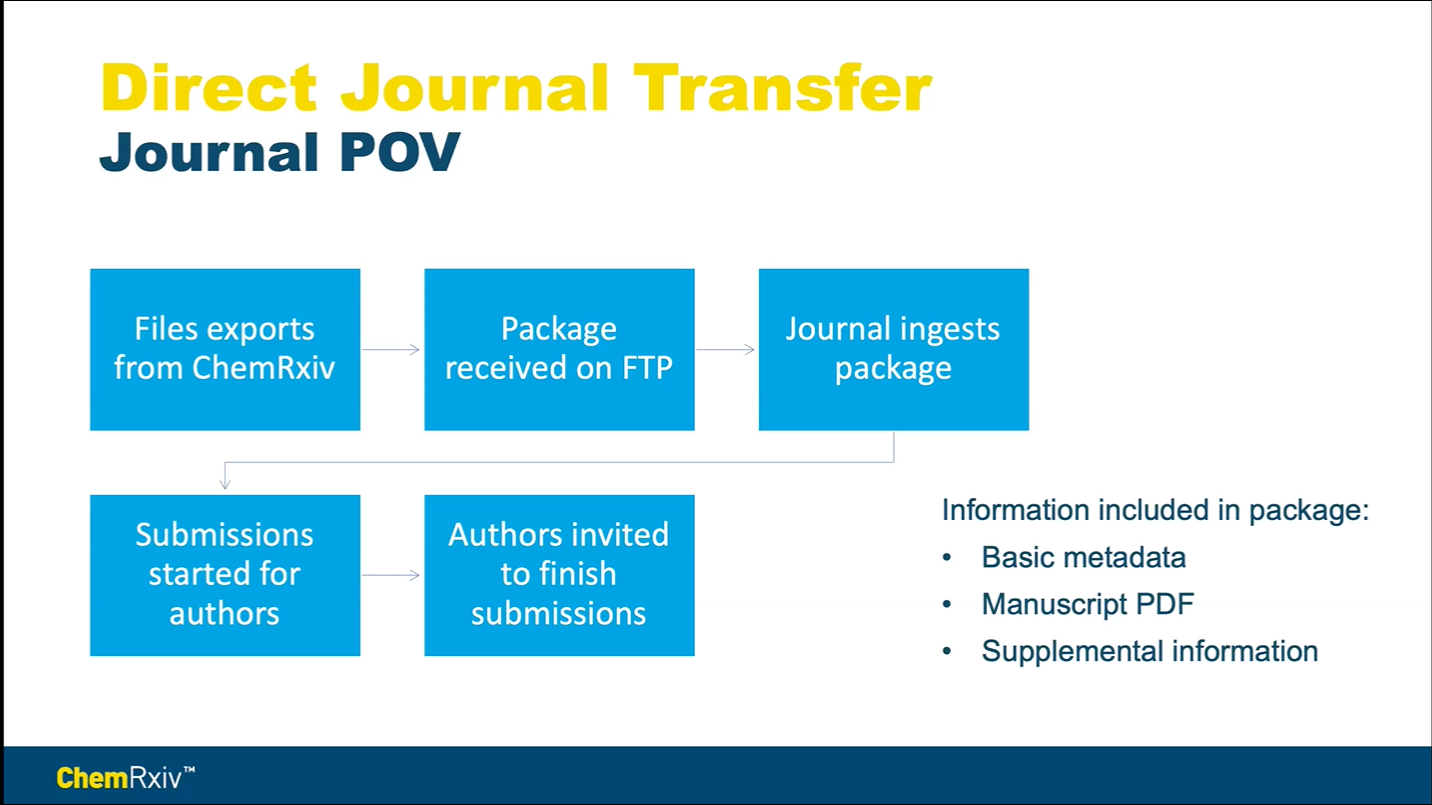
While the transfer process is relatively straightforward for the authors, there have been some challenges that ChemRxiv and its partner journals have had to consider during implementation. Leung noted that there are different submission systems between journals, journal submission forms are generally customized, and preprints collect less information than journal submission forms. Still, the direct transfer process makes it easy for authors to transfer their ChemRxiv preprints to a journal for consideration and further distribute their work through scholarly publishing.
In the closing presentation, senior product manager Sven Molter described the preprint options and configuration process at PLOS, which includes 12 journals spanning in scope across the portfolio. PLOS takes a holistic approach to open science through published peer review, protocols, data policy, credit, preprints, and methods.3 Molter contends that authors benefit from preprints in terms of access, transparency, and inclusivity as they “create a more efficient open peer review process, rapid dissemination of results” and more. Furthermore, preprints serve the field by allowing for community feedback, inclusion, and unlimited and timely updates.
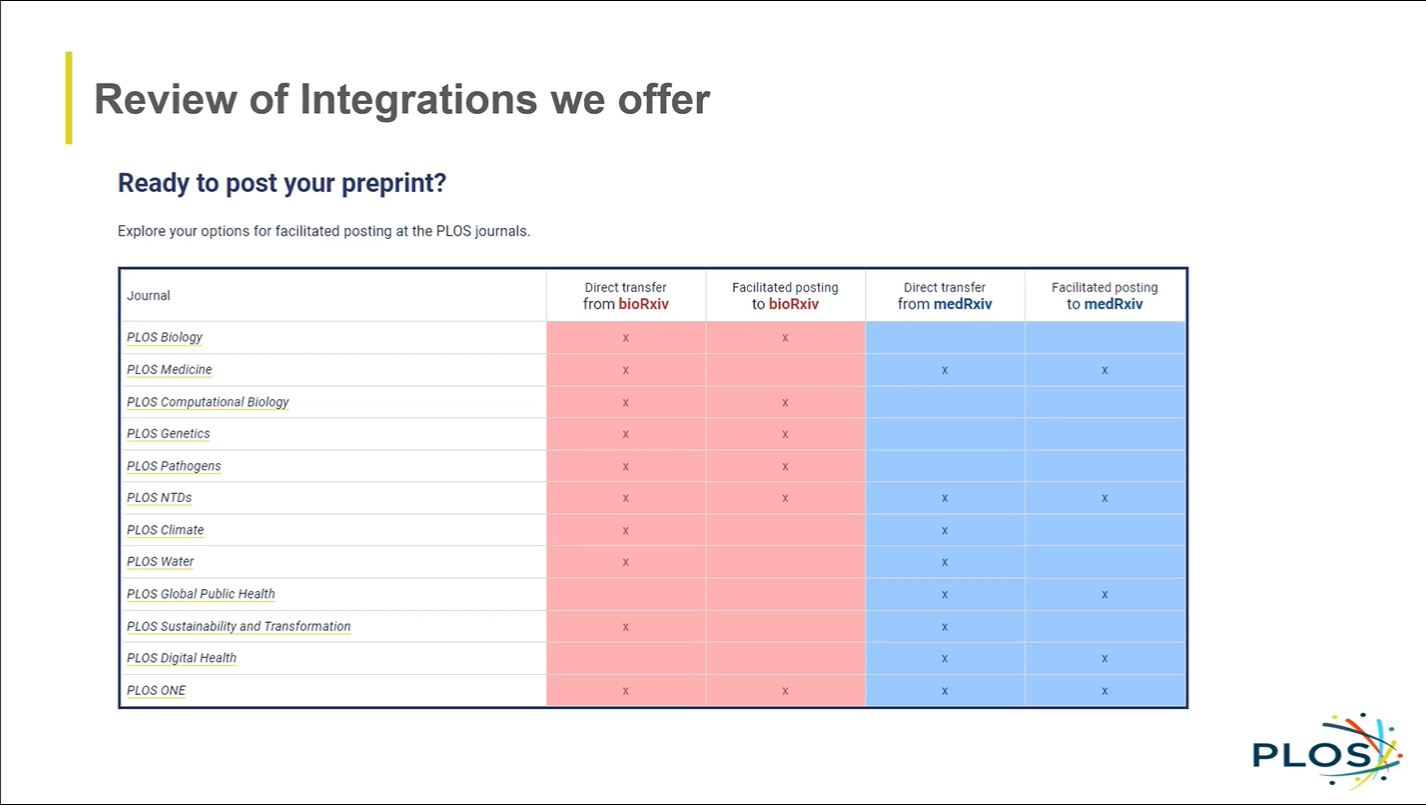
PLOS offers the following three different transfer options (Figure 3):
- Authors can directly transfer their preprints from preprint servers bioRxiv and medRxiv to a PLOS journal.
- At submission to a PLOS journal, authors can opt in to have their manuscript posted to bioRxiv or medRxiv, also known as “facilitated posting.”
- Authors can share the DOI to any specialized preprint server in which they deposit when they submit to a PLOS journal.
Molter outlined some strategies that PLOS implemented when integrating the transfer process into the journal submission form. The submission form leverages the data already collected during the preprint submission and uses nested questions so that authors do not have to answer duplicate or unrelated questions. The submission form builds upon the authors’ previous questions to ask only those that are applicable. For example, authors are initially asked if the manuscript has been posted as a preprint and, depending on that response, different follow-up questions are presented. PLOS also uses the submission form as an opportunity to educate authors on preprints, finding that balance between providing information and not overwhelming authors with a text-heavy form.
In order to develop that streamlined submission form, there are some hurdles to the configuration process that Molter recommends addressing in advance. Some of the challenges include working within the limitations of the submission system (e.g., how data links are scripted in the metadata) and negotiating the language used to make sure that the journal and preprint server are on the same page and have what they need. Molter suggests enlisting a professional project manager to coordinate between the journal team and the preprint server team, building out a project timeline that includes dedicated time for review and feedback, reviewing the technology early (e.g., describe use cases, make API materials available to the engineering team early to identify gaps and needs), and engaging with the marketing team to promote preprints and transfers to authors.
Looking ahead, PLOS seeks to work with additional servers to support facilitated postings in diverse topics and regions. PLOS has also experimented with incorporating preprint feedback into the traditional journal review process, with varying degrees of success, but plans to consider other experiments in the future.
As preprint transfers and cascading workflows continue to develop in parallel with the research and publishing landscape, the innovations to come will be added benefits to authors and journals.